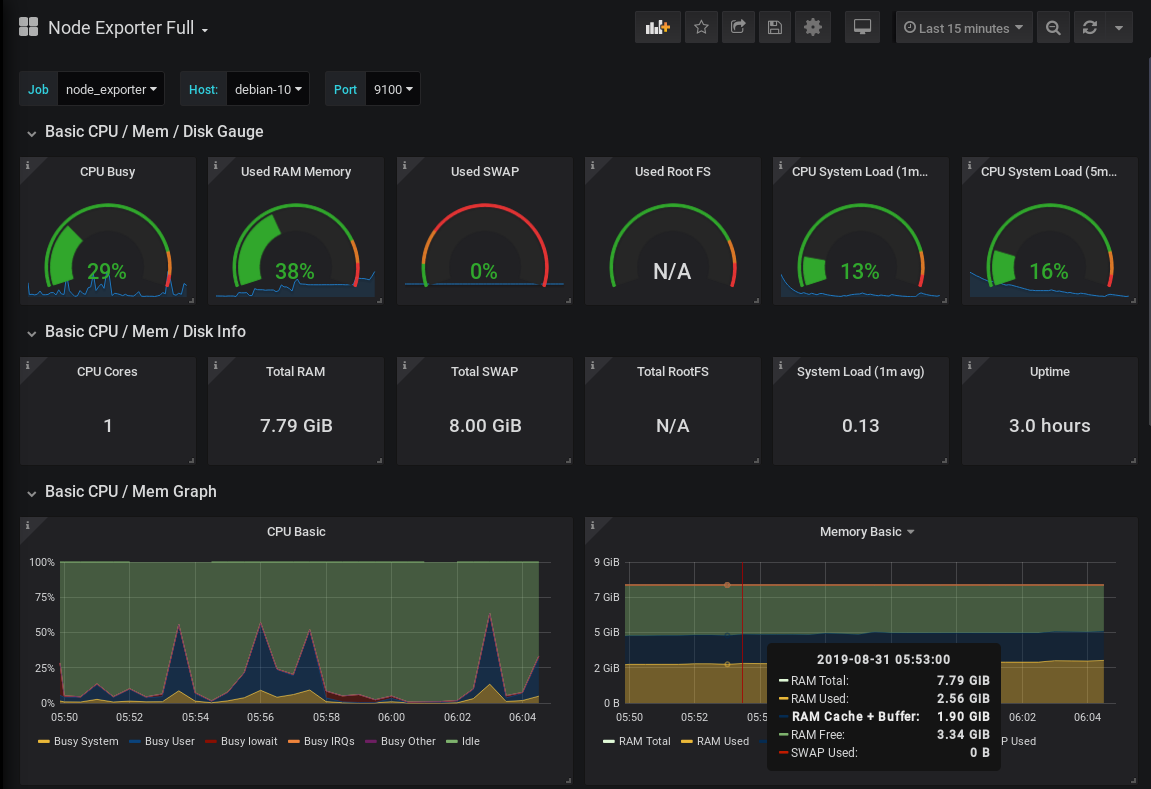
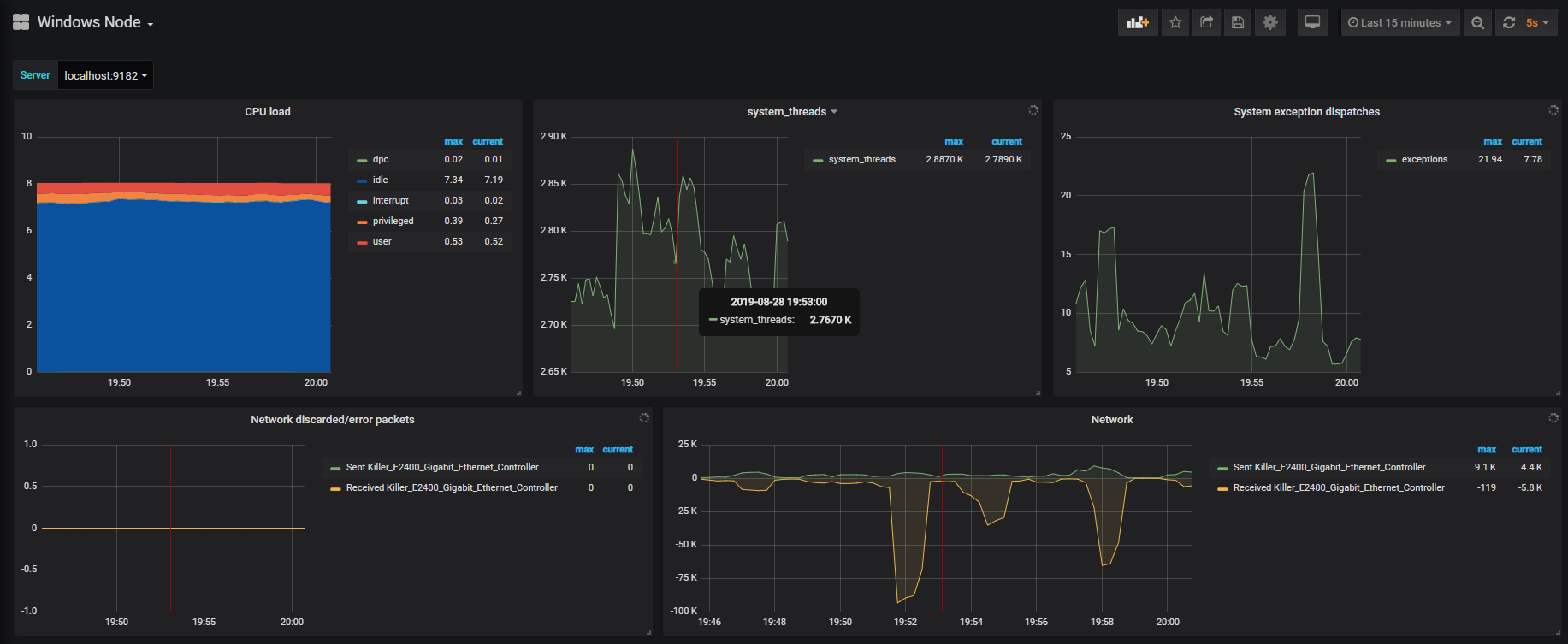
Learning the subject from various modern world options like podcasts, videos, blogs, expert classes, etc. can be your wishlist but reading a good book is the final order where people enjoy & gain knowledge without any loss. Hence, find the best software engineering books & kickstart your learnings.
Discovering the top-most Software engineering textbooks in 2021 can be difficult for everyone. But people who have viewed our article can find it very easily and effortlessly. As we are going to give you a compiled list of the best books on software engineering subjects where recommended by a few experts.
Before going to review all these top 10 best software engineering books in 2021 that are available in this tutorial, we want to suggest you view and remember a few factors that help you select the right book for your further learnings. They are as fashioned:
- High Recommendations
- Editor Reviews
- Hardcover/paperback
- Pricing
This tutorial completely focuses on the best software engineering books available for software engineers, developers, and project managers.
- 4 Best Open Source Dashboard Monitoring Tools In 2021
- 6 Tips To A Successful Code Review | Best Practices for Effective Code Review
- How To Install Git On Debian 10 Buster | Debian Git Repository | Debian Buster Git
Best New Software Engineering Books To Read in 2021
Software engineering is described as a process of analyzing user requirements and then designing, building, and testing software applications to fit those requirements. Guys who are beginners, or excited to learn coding, or expert ones can check the top 10 list of the best software engineering books 2021 below:
- Clean Code by Robert Martins
- Design Patterns: Elements of Reusable Object-Oriented Software by Eric Gamma
- Patterns of Enterprise Application Architecture by Martin Fowler
- Enterprise Integration Patterns by Gregor Hohpe
- The Mythical Man-Month by Frederick Brooks
- Code Complete by Steve McConnell
- Git for Teams by Emma Hogbin Westby
- Refactoring: Improving the Design of Existing Code by Martin Fowler
- The Art of Unit Testing by Roy Osherove
- Soft Skills: The Software Developer’s Life Manual by John Sonmez
1 – Clean Code by Robert Martins

Probably one of the greatest books about software engineering and programming. Every engineer, developer, or programmer should have read this book, at least one time.
In this book, Robert Martin provides clear and concise chapters about:
- How to write high-quality and expressive code;
- How to name your functions, your variables, essentially conveying your intent in your coding style;
- How to unit test properly, why it matters, and how to do it properly;
- How to choose relevant data structures and why they can make or break a piece of code;
- How to write comments but most importantly how NOT to write comments;
- How error handling works and how to properly engineer an exception handling workflow through your application or program
The book also provides real-life examples written in Java, so if you are familiar with object-oriented programming, that should not be an issue at all.
This book really helps to build code maturity. It actually helps you going from “How do I technically do this” to “How do I properly technically do this?” which is most of the time a neglected point by engineers.
Oh and for those who are wondering, what did the book from the introduction become?
I gave it to an aspiring Java engineer at my current job!
This book is ideal for junior developers and young software developers or engineers.
2 – Design Patterns: Elements of Reusable Object-Oriented Software by Eric Gamma

This software engineering book is a great follow-up to the Clean code manual.
As Clean Code gives you the foundations of programming, Design Patterns teaches you recipes to write manageable and scalable code.
For small or large programs, thinking about how to design it from the get-go is one of the mandatory skills of a good software engineer.
Most of the time, when designing a project, you don’t have to reinvent the wheel. You can open your design pattern book and pick one that fits your needs.
From there you have the guarantee that your project will be able to scale, and you are also given tools to scale it properly.
As examples, here are some design patterns that are taught in the book (and that I use on a daily basis)
- Abstract Factory: that lets you abstract object creation and decouples concrete objects from the business logic where they might be used;
- Observer: builds links between objects that allow them to be notified when a certain event occurs in one of them. Very useful for real-time applications or in industrial programs;
- Iterator: that enables developers to iterate on objects without knowing the implementation details of those data structures.
This book is really ideal for people willing to become either senior software engineers or solution architects.
Looking to master design patterns? Here’s where to get Design Patterns by Eric Gamma
3 – Patterns of Enterprise Application Architecture by Martin Fowler

Now that you know how to code, as well as how to design your code, it is time for you to know how to structure applications on an entreprise level.
Applications grow over time, and very often, they grow to a size that no one could have predicted.
However, you need to have concepts of entreprise architecture when you are building an application.
Are you correctly layering your application? If you are building a web application, are you aware of all the different presentational designs that you can choose from?
How are you accessing your data and how are you making sure that you are efficiently decoupling data from the applications that are trying to access them?
This book helps you master those concepts, and they can really play a big role in the life of an application.
This book, among other themes, teaches the following concepts :
- How to organize your domain and your business logic in your application;
- Techniques on how to access data in an application and how to build solid object-relational mappings for your databases;
- How to handle concurrency in applications and what patterns to use to avoid deadlocks;
- Web Presentations Patterns: MVC, MVVM, templates, are all equally useful in a world dominated by Javascript front-end frameworks.
- Data source architectural patterns: how to efficiently architecture your application depending on the data source that is residing behind it.
4 – Enterprise Integration Patterns by Gregor Hohpe

Even if you are working for startups, it is very unlikely that you will write programs as standalone tools, without any dependencies to other applications or without even communicating with them.
Applications do exchange data, they share information and they need to communicate in reliable ways.
Think about it, if you are withdrawing money at an ATM, how many different servers and databases will be contacted for every operation that you perform?
Probably a lot. And it needs to be fast and secure.
Those are the concepts taught in the book :
- What messaging patterns are and how they help to solve issues that were described right above;
- How to design messaging systems properly;
- An extensive list of individual messaging components (content-based router for example) that helps you build a complete architecture tailored to your needs;
- Real-life examples of how a banking system for example would actually be designed.
With this book, you will definitely get to know more about the capabilities of what we call an engineering architect or an entreprise architect.
Do you even own the book? I have my very own version of it!👽
Tip: for some of my interviews, I actually got asked questions related to concepts described in this book, especially how to handle system reliability in case of failure.
Probably one of the best software engineering books when it comes to system design.
5 – The Mythical Man-Month by Frederick Brooks
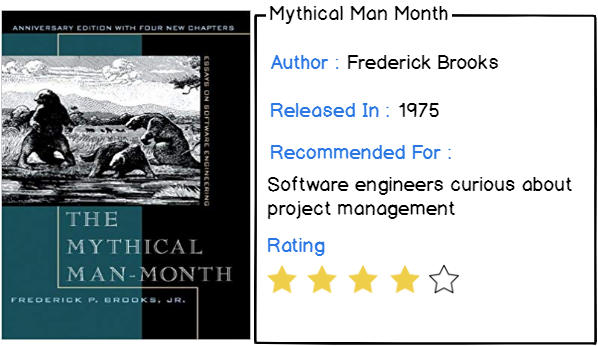
If you are following the project management path of your engineering carrier, this is probably the book you should read.
The Mythical Man-Month discusses productivity, essentially tackling one of the myths that the time taken by one engineer can be equally divided if you hire more engineers to do the job.
This is of course false, and Frederick Brooks explains several project management concepts related to this myth :
- Silver bullet concept: stating that there are no project management techniques able to solve current inherent problems of software development;
- How to handle delay in project delivery and what role projects owners have to endorse when it comes to their clients;
- How to communicate efficiently as a project leader, and what your team expects from you;
- Most importantly, how to manage project iteration and how to prevent the “second-system” effect.
In software engineering, even with the best developers, most of the project success relies on being able to manage your team efficiently.
Project management is a whole different skill set, and you are trying to succeed in this field, this is probably the book you should read.
This project management masterpiece is available right here.
6 – Code Complete by Steve McConnell

This book is seen as one of the references for software developers as it teaches all the basics that you should know in this field.
This is a very lengthy book, as it goes over 900 pages and sometimes in a lot of details.
With this book, you will cover :
- How to code and how to debug: including how to write programs for people first, and for computers second;
- Divide your code in terms of domains: the design of a high-level program is very different from the design (and implementation) of a low-level program;
- Master human qualities of top coders: this is very big in an industry where everybody thinks it has the ultimate answer to a question. Build humility, curiosity, but most importantly, keep your ego in check;
- Pick a process and stick to it: from the planning to the development, until the delivery, pick a process that guarantees project quality and prosperity.
7 – Git for Teams by Emma Hogbin Westby

For the seventh book, I chose a book about Git, the most used version control software in the world.
Why did I put this book in the list?
Because I believe that there can’t be a successful project without using version control, or without defining a good version control workflow.
If you are working alone, you may have not encountered issues that come with multiple people working on the same codebase at the same time.
However, without a proper workflow, the codebase can become quite a mess, and there is a very high chance that you will experience regressions.
This book teaches:
- What git is and how to use the different commands efficiently.
- How to define a custom git workflow for your team, given its size and what your project is about.
- How to conduct code reviews and why they matter in software integration.
- How to pick the best branching strategy for your team
- How to define roles in your team, who should be a contributor, a reviewer, who manages the codebase, and so on.
Do you need a guide on how to conduct a code review? Here are the 6 best code review tips for you to know.
8 – Refactoring: Improving the Design of Existing Code by Martin Fowler

As a software engineer, you spend a lot of time writing code and thinking about new algorithms in order to achieve your expected goal.
However, as your project grows, your codebase becomes larger and larger, you often find yourself writing duplicate functions, or having code parts that are very similar to one another.
As your project grows, you often feel like you are missing some points on function reusability and factorization.
Refactoring by Martin Fowler is a book that helps you synthesizing and factorizing your codebase.
The book is built on study cases, focusing on seventy different refactoring cases.
On those seventy refactoring cases, Martin Fowler describes how to perform them properly, in a safe way for the code base, as well as the role of unit testing in refactoring.
9 – The Art of Unit Testing by Roy Osherove

A software engineering book list would not be complete without a book focused on unit testing.
Unit testing is not important, it is crucial and essential if you want to deliver a good and qualitative piece of software to the end-user.
Not every functionality or line of code has to be tested, but you have to provide a reasonable amount of unit tests for crucial parts of your codebase.
Unit tests save lives.
When your codebase is rather small, you can’t foresee the immediate benefits of having extensive unit test coverage.
However, as your codebase grows, sometimes you may want to tweak a small and harmless part of your code.
Harmless? Never. I speak from experience, even when I could swear that my modifications had no impacts on the software, in reality, they had huge impacts on existing functionalities.
The Art of Unit Testing provides core competencies on how to unit test, how to scope it, and what to unit test.
The chapters focus on :
- What are the basics of unit testing, and how it differs from integration testing;
- What are stubs and mocks in unit testing frameworks;
- How to write loosely coupled unit tests in terms of dependencies;
- Understanding isolation frameworks extensively;
- How to work with legacy code from a testing perspective
Unit testing is crucial, and this is probably all you need to know to get your copy.
10 – Soft Skills: The Software Developer’s Life Manual by John Sonmez

I have followed John Sonmez from simpleprogrammer.com for a long time, and I respect John as an authoritative figure when it comes to soft skills designed for software engineers.
In a software engineering career, you spend most of your time coding, designing, and building software.
But as your responsibilities grow, you are sometimes given the opportunity to interact with clients, to gather their needs, or to actually showcase your advancement on its project delivery.
Interaction often means social skills, the ability to speak with confidence, the ability to choose the correct language given your audience, or the ability to negotiate.
Software engineering isn’t only about coding, it is also about maintaining a good work-life balance, having hobbies, exercising often, and eating properly.
Jon Sonmez helps you find and keep the right balance that you need to be an efficient and creative engineer, for a long time.
The books focus on:
- Productivity tips: how to build the right habits for you to triple down your productivity;
- Self-marketing tips: essentially how to sell yourself and how to increase your own perceived value;
- Fitness tips: how working out correlates with a good and healthy software engineering career, how it can benefit you on a daily basis;
- Financial advice: John explains how you can analyze your paycheck and make the best investments out of it.
Software engineering is not only about coding, get to know how to be more productive and have a great work-life balance.
Conclusion
Time to read and Time to practice are the best times to gain any knowledge you want.
Before ending this tutorial, there is one point that I want to make very clear when it comes to all the books.
True mastery comes from a reasonable amount of theory, and a tremendous amount of practice.
When practicing, you will get ten times more familiar with the concepts that you are reading about, and there are really no shortcuts to mastery in software engineering.
One of the greatest ways to keep learning when you are not at work, work on side projects!
Be patient, be humble, but also be confident that given the time, you will become a software engineer that delivers tools that really help people.
Experience is not taught in books.
Until then, have fun, as always.